Stakeholder Communication Plan – (Best Practices in 2025)
In a simpler world, a stakeholder communication plan would be a one-size-fits-all type of item. You could deliver the same notification to everyone with equally successful results. But in the real world, effective stakeholder engagement messages must be nuanced. The messages you send to different stakeholders when an incident occurs need to be tailored to […]
IT Service Alerting (ITSA) Tools Implementation Guide 2025
IT service alerting (ITSA) tools are quickly becoming must-haves. Networks are becoming more distributed, and IT teams are becoming more remote. Free network monitoring tools and patchwork incident management systems are no longer adequate for protecting your bottom line from system failures and network outages. Without enterprise-grade ITSA tools, it’s just a matter of time […]
Improvements in AlertOps 3.6.2.2
Minor Update: Improvements in 3.6.2.2 include minor updates, and improvements to the recent 3.6.2.1 update. *** Here’s a short list of important improvements: Out of Office – AlertOps now allows for on-call delegation for select groups, when you’re in multiple groups, and not truly out of office (OOF). Essentially, you could now be out of […]
Improvements in AlertOps 3.6.2.3

Minor Update: Improvements in 3.6.2.3 include minor updates, and improvements to the recent 3.6.2.2 update. *** Here’s a short list of important improvements: Navigation UI Enhancement – You can now have a much easier time navigating AlertOps with the new navigation UI enhancements. The (left) navigation bar now includes both hover and active states, making […]
Improvements in AlertOps 3.6.2.1

Minor Update: Improvements in 3.6.2.1 include minor updates, and improvements to the recent 3.6.2 release. *** Here’s a short list of important improvements: Live Call Routing Voicemails – Added the option to directly leave a message instead of automatically forwarding the call. Weekly Schedule Notifications – Sometimes separate teams want to know what the on-call […]
Updates in AlertOps 3.6.2

Minor Update: Update 3.6.2 includes minor updates to reporting filters along with a handful of important bug fixes & improvements! *** Here’s a list of changes: Workflow Enhancement – You can now add a bridge as part of a workflow, for an overall more smooth experience. Our belief is that this will make it easier […]
2023 Business Predictions: Is AI the Future of ITSM?

2023 could be the year of artificial intelligence (AI) in IT service management (ITSM). To gain deeper insights into this matter, let’s explore AI, its functioning, and its associated benefits. What Is AI? AI involves the use of machines that work and react like humans. Machines equipped with AI often use deep learning and natural […]
Updates in AlertOps 3.6.1

Minor Update: Update 3.6.1 includes minor updates to the UI and UX along with a handful of important bug fixes & improvements! *** Here’s a list of changes: New Navigation Icons – We’ve completely updated the side navigation icons. Our belief is this will make it easier to quickly identify important areas in the app, […]
What Is ITIL Incident Management, and What Does It Solve?
ITIL Incident Management refers to IT service management (ITSM) best practices aligned to an enterprise’s day-to-day activities. ITIL incident management, empowers enterprises to leverage IT to drive growth, transformation and change. There are five ITIL stages: Service Strategy: An enterprise defines its ITSM needs, assets and strategy. Service Design: An enterprise designs ITSM services, as well as systems […]
A DevOps Periodic Table of Critical Alert Monitoring System Integrations
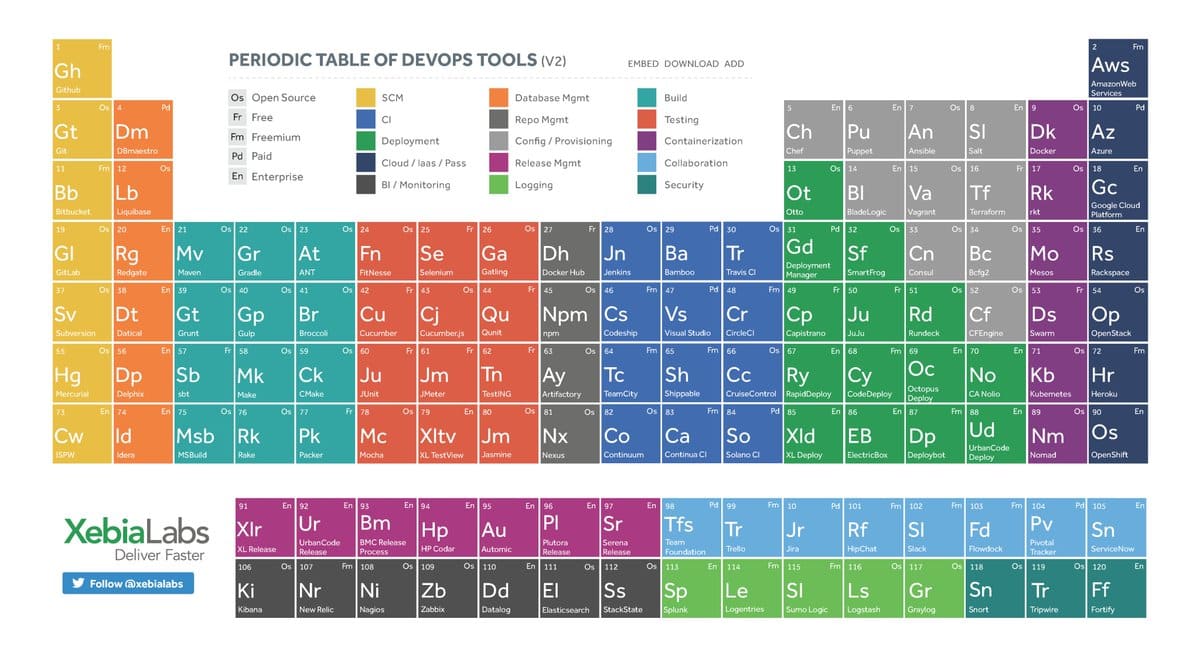
A development and operations (DevOps) team may deploy an alert tracking system to speed up incident response and resolution. Yet not all alert monitoring systems can be used in conjunction with everyday DevOps tools. Ultimately, choosing an alert tracking system that offers seamless integrations is key. With this system at its disposal, a DevOps team […]