Most “best alternatives” articles in this category are vendor-written and useless. They list six platforms, give each one a paragraph, and stop short of telling you what to actually do. We’ve been in roughly a hundred post-Opsgenie evaluations this year. We know who’s selling what at what price, which features are paywalled, where the migration stories are honest, and which platforms quietly raise their hand and which ones don’t fit.
This is the comparison we wish someone had written for us.
Seven platforms account for the bulk of every enterprise evaluation: AlertOps, PagerDuty, xMatters (now Everbridge), Rootly, incident.io, Atlassian JSM Operations, and Grafana Cloud IRM. The verdicts are below. Each platform gets a full breakdown after that. Then there’s a head-to-head section, a profile-based recommendation matrix, and a final call on what to do.
We sell one of these platforms. We’ll say so when we get there, and we’ll cite the same facts about AlertOps that we cite about everyone else. The goal here isn’t to win. The goal is to help you not pick wrong.
Quick reference: the seven platforms at a glance

Buyer-fit decision tree mapping organizational profiles to recommended Opsgenie alternatives across seven platforms, with AlertOps recommended for enterprise NOC environments requiring multi-channel response, bidirectional ITSM, and compliance-grade audit.
| Platform | Best for | Base pricing | On-call in base | AI in base | Support in base |
|---|---|---|---|---|---|
| AlertOps | Enterprise NOC, regulated industries, multi-channel response, bidirectional ITSM | Custom (responder-scaled) | Yes | Yes | Yes |
| PagerDuty | Engineering orgs with mature event routing, deep integration needs | $21-$41/user/mo + AIOps SKU | Yes | No (separate $699+/mo SKU) | Tier-gated |
| xMatters (Everbridge) | Enterprises pairing IT incidents with CEM/mass notification | $9-$39/user/mo | Yes (from Starter) | Yes (built in) | Tier-gated |
| Rootly | Mid-market DevOps living in Slack with Terraform-managed config | $20/user/mo + $20/user/mo on-call (separate) | No (separate product) | Light at Essentials, AI SRE Enterprise-only | Tier-gated |
| incident.io | Series B-D engineering teams wanting AI-forward Slack workflow | $15-$25/user/mo + on-call add-on | No ($10-$20/user/mo add-on) | Tier-gated (Pro+) | Tier-gated |
| Atlassian JSM Operations | Atlassian-standardized shops with Jira-using responders | ~$20-$48/agent/mo | Partial (advanced at Premium) | Tier-gated (Premium) | Tier-gated |
| Grafana Cloud IRM | Observability-led teams already standardized on Grafana | $20/active user/mo + Cloud base | Yes (merged into IRM) | Via broader Cloud | Tier-gated |
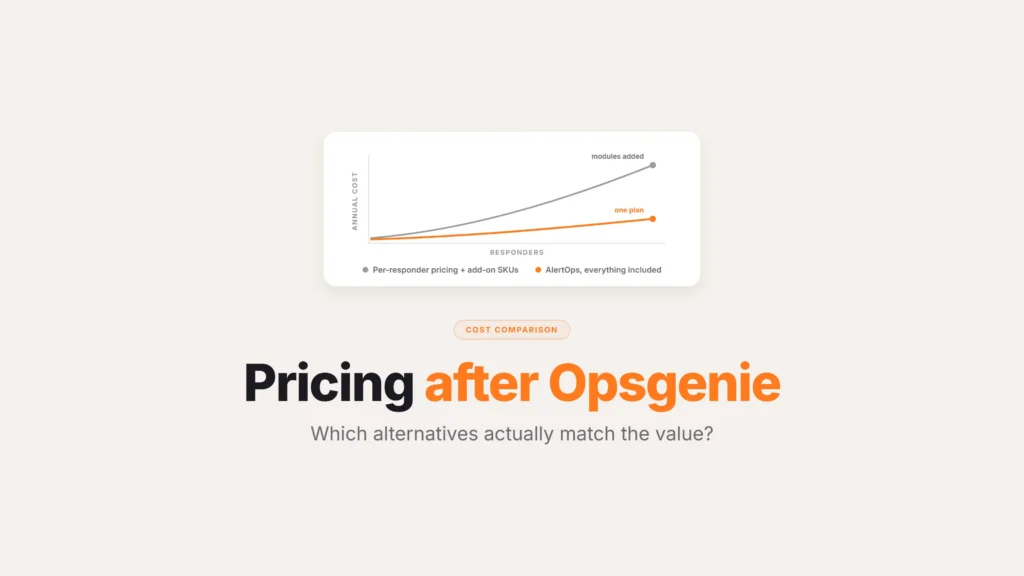
Two patterns to notice before reading further. First, on-call is bundled at five of seven platforms but sold separately at Rootly and incident.io. For organizations with 200+ responders, that single line item changes the total contract by tens of thousands of dollars a year. Second, AI is bundled at AlertOps and xMatters but separately priced or tier-gated at the other five. If your value from incident management depends on alert correlation and noise reduction (and at enterprise scale it usually does), the AI line shows up in the contract one way or another.
What actually matters in this comparison
Feature checklists are unreliable. Every platform on this list claims on-call, escalation, integrations, and AI. The real comparison dimensions are smaller and harder to fake.
What’s in the base plan, not what’s listed on the website. On-call, AIOps, audit-grade compliance, responsive support. Each platform either includes these in the seat price or sells them as a separate paid module. The platform with the lowest sticker price often turns into the most expensive once you add the modules you actually need.
Architectural layer. Incident response tools coordinate the human workflow after an alert becomes an incident. Incident orchestration platforms sit upstream, correlating signals before a responder sees them, then routing through multi-dimensional policies. Picking the wrong layer doesn’t show up the day you sign. It shows up nine months in, when the platform can’t bend the way the team needs it to.
Migration story. What actually carries forward from your Opsgenie configuration, what gets rebuilt, and how long the destination team estimates the cutover. Most platforms say “easy migration.” Few mean it.
Five-year contract math. The TCO at year five matters more than the price at year one. JSM’s first-year discount, PagerDuty’s AIOps consumption SKU, Rootly’s two-product structure, and incident.io’s stacked add-ons all behave differently when you compound them over five years.
With those four lenses in place, the deep dives below tell a clearer story than the website pricing pages do.
AlertOps
Verdict: The orchestration-layer fit for enterprise teams. Bundled commercial structure (AlertOps Enterprise bundles support, AI, and on-call) holds up at scale where others stack SKUs.
Best for: Enterprise environments in financial services, healthcare, telecom, data center operations, MSP, government, or critical infrastructure. Hundreds of services, multi-channel response across Slack, Teams, SMS, voice, email, and mobile, bidirectional ServiceNow or Jira ITSM as a non-negotiable, compliance-grade audit, AI alert correlation upstream of the responder queue.
Pricing reality: Custom, scaled to incident value rather than to seat count alone. Public published tiers exist (Premium at $18/user/mo annual, $22 monthly; Enterprise at $28/user/mo annual, $34 monthly) but most enterprise contracts negotiate to the responder topology rather than the per-seat list. AlertOps deals tend to win on TCO at 200+ responders because the bundling holds. Onboarding fee is typically $3,000 and often waived during contract negotiation.
Strengths:
- The Smart Correlation Engine inside OpsIQ produces up to 68% alert noise reduction in enterprise deployments. Verified on the OpsIQ product page.
- Agent Chronicle generates an automated postmortem with structured audit trail underneath. Regulated industries need this artifact class; most response tools don’t produce it as a standard output.
- Multi-channel response treats six channels as architectural peers through one policy engine. The chat-first platforms produce missed pages at off-hours; AlertOps doesn’t because voice, SMS, and mobile with DND override are first-class wake-up surfaces.
- ServiceNow integration is bidirectional and “purposely built add-on” rather than competitive. Customers who run ServiceNow as ITSM standard get a complementary tool, not a fight over the same workflow surface.
- The Opsgenie migration is included as an assisted Solution Engineering engagement. 100+ enterprise Opsgenie migrations completed; one recent engagement wrapped 200 users in three working sessions.
Migration from Opsgenie: Three to twelve weeks depending on environment complexity. Automated tool handles users, groups, schedules, and escalation policies (with the per-policy Workflow / Response Play / Escalation Policy decision made by the SE team). Solution Engineering team handles audit, integration migration, cutover planning, and clean Opsgenie deprovisioning. Included in AlertOps Enterprise. Not a self-serve tool. Assisted program.
PagerDuty
Verdict: The longest-running and deepest dedicated incident response platform, with the broadest integration catalog. Headline pricing is fine. Real TCO at enterprise scale gets stacked across multiple SKUs, and the per-feature paywall pattern walks customers away.
Best for: Engineering organizations already standardized on PagerDuty with years of operational tuning in the escalation engine. Organizations whose budget can absorb AIOps as a separate consumption SKU. Mid-market teams with bounded responder populations.
Pricing reality: Professional at $21/user/mo annual, Business at $41/user/mo annual. AIOps starts at $699/month annual ($799 monthly) as a separate consumption-based SKU layered on top of an IM seat. Customer Service Operations and Automation are additional paid modules. For enterprise alert volumes, the AIOps line frequently becomes the largest item in the contract.
What’s in the base plan: On-call scheduling and escalation policies (the most mature engine in the category), incident response workflow, integration catalog (broadest by raw count in the market), mobile app, API, basic reporting.
What’s not: AIOps event correlation and noise reduction ($699+/month annual consumption SKU), Customer Service Operations, Automation Actions, premium integrations, 24/7 phone support (Business and Enterprise tiers only), and dedicated CSM (Enterprise).
Strengths:
- Deepest integration catalog in the category. Long-tail observability tools, niche ITSM products, and obscure cloud services all have PagerDuty connectors when they don’t have anyone else’s.
- Mature event routing engine with edge cases tested across millions of incidents over a decade.
- Spring 2026 Release expanded AI partner ecosystem to 30+ vendors and shipped MCP plugins for Claude Code and Cursor. The SRE Agent is evolving into a virtual responder that joins escalation policies.
- Public-company vendor relationship satisfies enterprise procurement requirements that some teams have.
Honest weaknesses:
- The “giant bucket” management problem. A 200-user dev tools platform that migrated from PagerDuty to Opsgenie described it bluntly: “PagerDuty was kind of this thing where it was just this giant bucket of a bunch of routing rules and alerts and all that, and we hated that because from a management perspective it was just impossible to keep everybody straight.” Multiple teams that left PagerDuty cite the same structural issue.
- Per-feature paywall pattern. A mid-market US IT operations lead trialing PagerDuty Pro: “Every advanced feature pretty much in the platform is paywalled behind an $800 upgrade. We’re not going to pay that much for alerting. So we’re looking at other alternatives now.”
- AIOps as a separate consumption SKU compounds with event volume. Enterprise environments running 200+ services hit AIOps bills that exceed the IM seat line.
- Multi-SKU TCO at scale is unpredictable. IM + AIOps + Customer Service Operations + Automation produces contracts that look different in year three than in year one.
Migration from Opsgenie: Available via PagerDuty’s migration services program. Scope and cost vary by environment. Not free by default.
xMatters (Everbridge)
Verdict: Credible enterprise platform with strong flow-based communication workflows. Best fit when you already use Everbridge for Critical Event Management. Post-acquisition product velocity is slower than independent peers.
Best for: Enterprises that already run Everbridge CEM for physical-safety and mass-notification use cases. Teams that want IT incident response under the same vendor as the broader resilience stack. Regulated industries pairing IT incidents with compliance-grade notification.
Pricing reality: Starter $9/user/mo, Base $39/user/mo, Advanced custom. On-call and AI are bundled into paid tiers from Starter upward, which is unusual for the category and actually competitive on TCO when you do the math at responder scale.
What’s in the base plan: On-call scheduling (included from Starter), flow-based workflow designer, multi-channel notification, AI capability (xMatters AI Agent launched November 2025), integration marketplace, mobile app.
What’s not: 24/7 support (Base and Advanced tiers only; Starter is 8×5). Some compliance and audit features tier-gate at Advanced.
Strengths:
- Real bundling. On-call plus AI in paid tiers without separate consumption SKUs. The AI Agent ships in the Incident Console with runbook suggestions and resolver recommendations.
- Flow-based communication workflows are mature and battle-tested in regulated industries.
- CEM integration with Everbridge is real and tight. For organizations running mass notification for physical events alongside IT incident response, the single-vendor story works.
Honest weaknesses:
- Post-Everbridge acquisition product velocity. The roadmap has to share engineering attention with the broader Everbridge portfolio, which slows feature shipping compared to independent peers like AlertOps or incident.io.
- UI feels dated relative to modern Slack-native tools. A team that’s used to the polish of incident.io will find xMatters more workman-like.
- The CEM overlap is a feature for some buyers and irrelevant for others. If you don’t already use Everbridge, the value proposition is weaker.
Migration from Opsgenie: Everbridge provides migration services but they aren’t free by default. Scope depends on environment complexity.
Rootly
Verdict: Best-in-class Slack-native incident response workflow for mid-market DevOps. Terraform-managed configuration is genuinely differentiated. On-call is a separately licensed product that doubles the per-user cost at the configuration most teams actually buy.
Best for: Mid-market DevOps and platform engineering teams that live in Slack. Organizations that want Terraform-managed configuration for infrastructure-as-code workflows. Teams running modern post-incident learning practices.
Pricing reality: Incident Response Essentials at $20/user/mo. On-Call Essentials at $20/user/mo as a separately licensed product. A team that wants both incident response and on-call (which is most teams) effectively pays $40/user/mo. AI SRE is Enterprise-only on top of both.
What’s in the base plan (IR Essentials): Slack-native incident workflow, catalog model (services, components, teams), integrations, post-incident review workflow, basic AI features (Scribe, Similar Incidents), Terraform provider for configuration-as-code.
What’s not: On-Call (separate $20/user/mo product), Rootly AI SRE agent (Enterprise-only), dedicated CSM (Enterprise-only), and Priority 24/7 Global Support (Enterprise-only).
Strengths:
- Slack-native incident workflow is genuinely best-in-class. The product feels designed by people who use it.
- Terraform-managed configuration resonates with platform engineering teams. Configuration-as-code for incident response is a real differentiator.
- Rootly AI Labs program (launched at GitHub HQ) and continued investment in the AI SRE agent show active product velocity.
- Strong post-incident learning practices baked in.
Honest weaknesses:
- Two-product packaging structure. IR Essentials at $20/user/mo plus On-Call Essentials at $20/user/mo gets you to $40/user/mo before adding the AI SRE agent. For organizations where on-call is the primary use case (most post-Opsgenie environments), the two-product structure changes the TCO comparison significantly.
- AI SRE is Enterprise-only, which means the flagship AI capability is gated behind a tier most mid-market teams don’t reach.
- Enterprise-tier features (multi-tenancy, advanced ITSM, deep compliance) are thinner than purpose-built enterprise platforms.
Migration from Opsgenie: Rootly provides migration support, but the two-product structure means you’re configuring two products rather than one. Effort is moderate.
incident.io
Verdict: Excellent Slack-first incident response with genuinely differentiated AI investigation agents. On-call as a paid add-on, AI features tier-gated to Pro and above. The PagerDuty Rescue Program (contract buyouts plus AI-assisted migration) is one of the more aggressive customer-acquisition plays in the category right now.
Best for: Series B through Series D engineering and SRE teams that want a Slack-first, AI-forward incident workflow with strong post-incident learning loops. Companies whose responder population overlaps cleanly with the engineering team.
Pricing reality: Team tier at $15/user/mo annual ($19 monthly). Pro tier at $25/user/mo annual. On-call is a paid add-on: $10/user/mo on Team, $20/user/mo on Pro, or $20/user/mo as a standalone On-call only plan. Only the free Basic tier includes single-team on-call. AI Suggestions, AI Scribe, and the AI chat agent require Pro or Enterprise.
What’s in the base plan (Team tier): Slack-native incident workflow, catalog (limited), status pages, post-incident review, integration marketplace, basic AI features.
What’s not: On-call (paid add-on), AI Suggestions, AI Scribe, and AI chat agent (Pro+), custom catalog types (Pro+), dedicated Slack channel from incident.io customer success (Pro+), live phone support (Enterprise-only), and SLAs (Enterprise-only).
Strengths:
- Best-in-class post-incident learning and catalog model.
- AI investigation agents are genuinely differentiated. Recent $62M Index Ventures round funded the push into AI agents that “resolve incidents with you.”
- Slack-first UX is polished and adopted quickly by engineering teams that already live in chat.
- The PagerDuty Rescue Program (contract buyouts up to a year free, AI-assisted migration) is an aggressive go-to-market motion that signals active customer acquisition.
Honest weaknesses:
- Stacked add-on pricing. Team tier plus on-call add-on plus AI Pro features gets to roughly $35-$45/user/mo before Enterprise tier features. For organizations whose responder population extends beyond the engineering team, this compounds quickly.
- On-call as a paid add-on creates real friction at the configuration most post-Opsgenie teams need. The free Basic tier includes only single-team on-call, which won’t scale.
- Bi-directional ITSM (ServiceNow, complex Jira workflows) and MSP multi-tenancy are thinner than purpose-built enterprise platforms.
- Live phone support is Enterprise-only. For teams whose incident response runs hot at 2 AM, this isn’t theoretical.
Migration from Opsgenie: incident.io’s PagerDuty Rescue Program (which also accepts Opsgenie migrants) offers contract buyouts and AI-assisted migration. Aggressive offer but bundled with the standard tier-gating.
Atlassian JSM Operations
Verdict: Atlassian’s recommended path with a real 58%/40% Year 1/Year 2 discount that gets attention. Works for Atlassian-standardized teams whose responders are all Jira users. Falls apart when your responder population extends beyond Jira or your ITSM standard is ServiceNow.
Best for: Organizations already standardized on the Atlassian stack (Jira, Confluence, Bitbucket, Compass) where the responder team overlaps cleanly with the Jira-using engineering team. Teams that want incident management folded into the broader ITSM workflow under one vendor relationship.
Pricing reality: JSM Standard at approximately $20/agent/mo annual (about $23.80 monthly). JSM Premium at approximately $48/agent/mo annual (about $53.30 monthly). Enterprise tier is custom and annual-only, typically six figures. The 58% Year 1 / 40% Year 2 discount for Opsgenie migrants is real and frequently quoted by prospects from memory. Year 3 returns to list pricing, which changes the five-year math.
What’s in the base plan (Standard): Basic on-call scheduling, basic alert routing, basic Jira integration, JSM service desk.
What’s not (Standard, gates at Premium): Advanced alert integrations, incident investigation, major incident management, CMDB, Rovo AI agents, AI-powered ops, advanced support SLAs. Effectively, the features enterprise teams actually need for production incident response sit at Premium pricing.
Strengths:
- Native integration with Jira, Confluence, Compass, Bitbucket. For Atlassian-standardized teams, single-vendor procurement and one consolidated commercial relationship are real value.
- 58%/40% Year 1/Year 2 discount is the most aggressive recruitment offer in the category. Mid-market teams quote the numbers from memory during evaluation calls.
- Rovo AI agents (at Premium and above) bring Atlassian’s broader AI investment into the operations workflow.
- One vendor for ITSM, dev tickets, and on-call simplifies procurement.
Honest weaknesses:
- Per-agent pricing. JSM Operations seats are JSM agent seats. For organizations whose responder population includes operators, vendor contacts, and stakeholders outside Jira, the agent math gets worse fast. A Fortune 500 retail operations VP described the dynamic: “Honestly, I don’t think we have a lot of use for it outside of the on-call stuff because we use ServiceNow for our ITSM stuff.”
- ServiceNow conflict. JSM is itself an ITSM platform and isn’t architected as a complementary peer to ServiceNow. For ServiceNow-standardized enterprises, JSM Operations creates a second ITSM-adjacent system running in parallel.
- The Year 3 discount cliff. The 58%/40% offer expires after Year 2, and by then your migration runway off JSM is gone. The “compelling Year 1” decision compounds into a five-year commitment at full list price.
- The data model treats incidents as JSM ticket types. That’s appropriate for service requests, not for the orchestration model enterprise incident response actually requires.
- Real operations capability requires Premium tier ($48/agent/mo). At that price point, AlertOps and other purpose-built alternatives win on TCO.
Migration from Opsgenie: In-app migration guide is generally available. Atlassian sales motion is heavy. Migration assistance is built into the Atlassian customer success motion but doesn’t fundamentally change the per-agent pricing structure that drives most evaluations away.
Grafana Cloud IRM
Verdict: The right choice for observability-led teams already standardized on the Grafana stack. Cheap, tightly integrated with metrics/logs/traces. Cloud-only after the OSS version was archived. Thin on enterprise ITSM, MSP, and compliance breadth.
Best for: Engineering teams already running Grafana Cloud for observability who want lightweight on-call and incident response inside the same stack at low marginal cost. Cost-sensitive technical teams comfortable with cloud-only deployment.
Pricing reality: Grafana Cloud Free includes 3 active IRM users with community support. Pro adds users at $20 per active IRM user per month beyond the 3 free seats, plus Grafana Cloud base subscription (from $19/month with usage). Enterprise commits start at $25,000/year.
What’s in the base plan (Pro): On-call scheduling (merged with Grafana Incident into unified IRM application as of 2026), incident response workflow, tight integration with Grafana metrics/logs/traces, integrations with Grafana ecosystem.
What’s not: Premium support (Enterprise-only). Self-hosted deployment (Grafana OnCall OSS entered maintenance mode March 2025 and was archived March 24, 2026; cloud-only is the only forward path). Deep bi-directional ITSM. MSP multi-tenancy. Compliance-grade audit as a first-class output.
Strengths:
- Tightest possible integration with Grafana metrics, logs, and traces. For observability-led teams, the alert-to-incident path is essentially native.
- Cheapest credible path for teams already on Grafana Cloud. Marginal cost of adding IRM is low.
- Migration tooling exists for PagerDuty, Opsgenie, and Splunk OnCall users moving to the cloud product.
- Grafana Cloud IRM consolidation (OnCall + Incident merged into one application) cleans up the previous two-product confusion.
Honest weaknesses:
- Cloud-only after the OSS archival. Air-gapped and regulated buyers that require on-premise deployment are blocked.
- ITSM bi-directional sync is thinner than purpose-built incident orchestration platforms. ServiceNow and Jira work, but as integrations rather than as architectural peers.
- MSP multi-tenancy is limited. Managed service providers serving multiple end customers find the model constrained.
- Enterprise compliance-grade audit artifacts (the structured, timestamped, immutable incident record regulators expect) aren’t the product’s design center.
- Forward development depends on Grafana Labs’ broader Cloud strategy. The roadmap is observability-led, which is right for the target customer and limiting for everyone else.
Migration from Opsgenie: Migration tool exists. For teams already running Grafana, the lift is moderate. For teams not on Grafana, you’re effectively adopting two platforms at once (observability plus IRM), which isn’t the same evaluation.
Head-to-head: how AlertOps compares to each major alternative
The per-platform breakdowns above give you the structured view. The head-to-head matchups below give you the matchup-specific answer.
AlertOps vs PagerDuty
The two platforms occupy different architectural layers. PagerDuty operates primarily as incident response with AIOps as a separate paid layer. AlertOps operates as incident orchestration with everything bundled. At small responder counts and bounded alert volume, PagerDuty’s mature engine and broad catalog can win. At enterprise scale (200+ responders, hundreds of services, multi-channel response requirements, bidirectional ITSM as a non-negotiable), AlertOps wins on architecture and TCO. The decisive variable is usually whether the AIOps SKU is on your contract.
AlertOps vs xMatters
Both bundle on-call and AI. The choice usually turns on whether you already use Everbridge CEM. If yes, xMatters is the coherent continuation. If no, AlertOps wins on product velocity (independent vendor, faster shipping) and on multi-channel orchestration depth. xMatters’s flow-based workflow designer is more sophisticated for communication scenarios; AlertOps’s policy engine is more sophisticated for incident orchestration scenarios.
AlertOps vs Rootly
Different fit profiles. Rootly is the right choice for mid-market DevOps teams that want Slack-native workflow with Terraform-managed configuration. AlertOps is the right choice for enterprise teams that need multi-channel response, bidirectional ITSM at architectural-peer depth, and compliance-grade audit. The pricing reality matters: at the configuration most teams actually need (IR plus On-Call), Rootly is $40/user/mo to AlertOps’s bundled pricing structure.
AlertOps vs incident.io
Similar fit dynamics to the Rootly comparison. incident.io’s AI investigation agents are genuinely differentiated and best-in-class for Slack-first engineering teams. AlertOps wins for enterprise environments where on-call needs to scale beyond engineering, where ServiceNow is the ITSM standard, where multi-channel response is non-negotiable, or where compliance-grade audit is required. The stacked add-on pricing (Team plus on-call plus AI Pro features) at incident.io changes the comparison at enterprise responder counts.
AlertOps vs JSM Operations
The Atlassian discount is real and gets attention. The Year 3 cliff is also real and gets less attention. For Atlassian-standardized teams whose responders are all Jira users, JSM works. For everyone else (ServiceNow-standardized, responder population beyond engineering, compliance-grade audit requirements, real operations capability beyond JSM Standard tier), AlertOps wins on architecture and TCO. The math gets clearer when you project the contract across five years rather than two.
AlertOps vs Grafana Cloud IRM
Different categories, really. Grafana Cloud IRM is the right choice if you’re already running Grafana Cloud for observability and want lightweight on-call inside the same stack. AlertOps is the right choice if you need enterprise orchestration depth with bidirectional ITSM, MSP multi-tenancy, or on-premise deployment options. Most enterprise teams that evaluate both end up picking based on whether they’re already a Grafana shop.
What to choose based on your profile
Six profiles cover most post-Opsgenie evaluation outcomes.
Software-first engineering team, 100-500 engineers, response lives in Slack, post-incident is a learning culture. Choose incident.io. Plan for the on-call add-on from the start. Budget for AI Pro features in year two.
Mid-market DevOps team, infrastructure-as-code culture, Terraform-managed everything, Slack-native workflow. Choose Rootly. Plan for both products (IR plus On-Call) at $40/user/mo combined. AI SRE is Enterprise-only, so consider whether you’ll reach that tier.
Atlassian-standardized organization, responders are Jira users, modest on-call requirements. Evaluate JSM Operations alongside one alternative. The 58%/40% discount is real for two years. The Year 3 cliff is real after that. Run the five-year math.
Engineering organization already on PagerDuty with mature event routing. PagerDuty fits. Plan AIOps as a separate consumption SKU rather than treating it as optional. Multi-SKU TCO at enterprise scale requires careful procurement.
Enterprise running Everbridge CEM for physical resilience and mass notification. xMatters fits as the IT incident response layer under the same vendor. Post-acquisition product velocity is the trade-off to weigh.
Observability-led team already on Grafana Cloud. Grafana Cloud IRM is the cheapest credible path. Plan around cloud-only deployment if you have compliance requirements for on-prem.
Enterprise operations team, multi-tier NOC, 200+ services, multi-channel response across Slack/Teams/voice/SMS/email/mobile, ServiceNow as ITSM standard, compliance-grade audit required. AlertOps fits the orchestration-layer requirements. Bundled commercial structure holds at scale. Free Opsgenie migration as an assisted Solution Engineering engagement removes the rebuild risk.
The verdict
There isn’t one winner because the post-Opsgenie market has real category splits. The honest verdict is profile-specific. For most enterprise environments in financial services, healthcare, telecom, data center operations, MSP, government, or critical infrastructure, AlertOps is the architectural and commercial fit. For Slack-native mid-market engineering teams, incident.io or Rootly fits better. For Atlassian-standardized teams whose responders are all Jira users, JSM Operations is the natural path. For Everbridge CEM customers, xMatters is the coherent continuation. For Grafana-stack teams, Grafana Cloud IRM is the cheapest fit.
The mistake most teams make is evaluating on per-seat sticker price rather than on what’s actually in the base plan. The cheapest seat on the shortlist usually isn’t the cheapest contract. Verify what’s bundled, what’s separate, and what’s tier-gated before comparing prices.
A mid-market team in the middle of their Opsgenie replacement put the evaluation discipline cleanly: “if it does everything OpsGenie does, that’s fine, but if we’re switching tools, make sure we’re getting the best tool for us for the functionality we need.” That’s the right test. Run it across the seven platforms and the answer narrows fast.
Book a demo at alertops.com/demo if your profile points at orchestration and you want to see how the AlertOps comparison plays out against your specific shortlist.
Frequently asked questions
What are the best Opsgenie alternatives for enterprise teams in 2026?
The seven platforms most enterprise teams evaluate in 2026 are AlertOps, PagerDuty, xMatters (Everbridge), Rootly, incident.io, Atlassian JSM Operations, and Grafana Cloud IRM. Each fits a different operating profile. AlertOps fits enterprise orchestration requirements at multi-channel, bidirectional ITSM, compliance-grade audit scale.
What is the difference between AlertOps and PagerDuty as Opsgenie replacements?
AlertOps operates at the incident orchestration layer with OpsIQ upstream correlation, Agent Chronicle automated postmortems, multi-dimensional policy routing, and AI and support in AlertOps Enterprise. PagerDuty operates as incident response with on-call bundled but AIOps as a separate consumption SKU starting at $699 per month annual. At enterprise scale the comparison turns on bundled-vs-stacked TCO, multi-channel orchestration depth, and the per-feature paywall pattern that walks PagerDuty customers away.
Is Atlassian JSM Operations a good Opsgenie replacement?
For Atlassian-standardized teams whose responders are Jira users, JSM Operations can work. The 58% Year 1 / 40% Year 2 discount is real and aggressive. The Year 3 cliff is also real. For ServiceNow-standardized teams, teams with responders outside Jira, or teams needing real operations capability beyond JSM Standard tier, JSM Operations is not the architectural fit.
Why do Rootly and incident.io sell on-call as a separate product?
Strategic positioning. Both platforms grew up as Slack-native incident response tools and added on-call later. Rootly On-Call Essentials is a separately licensed $20/user/mo product alongside the $20/user/mo IR Essentials. incident.io on-call is a paid add-on at $10-$20/user/mo per tier or a $20/user/mo standalone plan. For post-Opsgenie buyers where on-call is the primary use case, the two-product structure meaningfully changes the TCO comparison.
Which Opsgenie alternative offers a free migration?
AlertOps includes the Opsgenie migration as an assisted Solution Engineering engagement in AlertOps Enterprise. incident.io’s PagerDuty Rescue Program offers contract buyouts and AI-assisted migration for displaced PagerDuty and Opsgenie customers. Grafana Cloud IRM provides a migration tool for PagerDuty, Opsgenie, and Splunk OnCall users. PagerDuty and others offer migration services with varying scope and cost; verify specifics during evaluation.
How long does it take to migrate from Opsgenie to a new platform?
Six to twelve weeks for enterprise environments, two to six weeks for smaller deployments. The variable isn’t the destination platform’s migration tooling. It’s the complexity of the source Opsgenie configuration: number of integrations, custom routing logic, depth of operational tuning. The clean migrations follow a six-phase playbook (audit, export, map, import, parallel-run cutover, post-migration audit).
Which Opsgenie alternative is cheapest?
Cheapest sticker price isn’t cheapest TCO. xMatters Starter ($9/user/mo) and JSM Standard (~$20/agent/mo) and incident.io Team ($15/user/mo without on-call) have the lowest entry pricing. Real TCO depends on which modules you actually use; Rootly’s two-product structure, incident.io’s stacked add-ons, PagerDuty’s AIOps SKU, and JSM’s Year 3 cliff all change the math. AlertOps bundled pricing frequently wins on TCO at enterprise responder counts because nothing gets unbundled.
Should I pick the same platform as my last company?
No. The right platform depends on the operating model of your current organization, not on what you used to use. Engineering teams that loved PagerDuty at one company often find PagerDuty inappropriate at the next because the new responder population and ITSM standard are different. Run the profile-based evaluation in this article against your current org, not against your familiarity.