
Opsgenie did one thing well: standalone on-call and alerting at per-responder pricing, with a deep integration marketplace and a focused product roadmap. That’s why enterprise teams adopted it. It is also why Atlassian’s decision to fold it into Jira Service Management Operations after the June 4, 2025 end-of-sale created a real evaluation gap, because the product Atlassian is recommending is not the product that won those enterprise customers in the first place.
This guide compares AlertOps and Opsgenie across the dimensions that mattered when Opsgenie was being chosen and the dimensions that matter now when teams are choosing a successor. The objective is not to declare Opsgenie obsolete (it isn’t, until the EOL date) or AlertOps perfect (no platform is). The objective is to surface where AlertOps preserves what Opsgenie did well, where it extends what Opsgenie did not address, and where it shifts the commercial structure in ways that matter at enterprise scale.
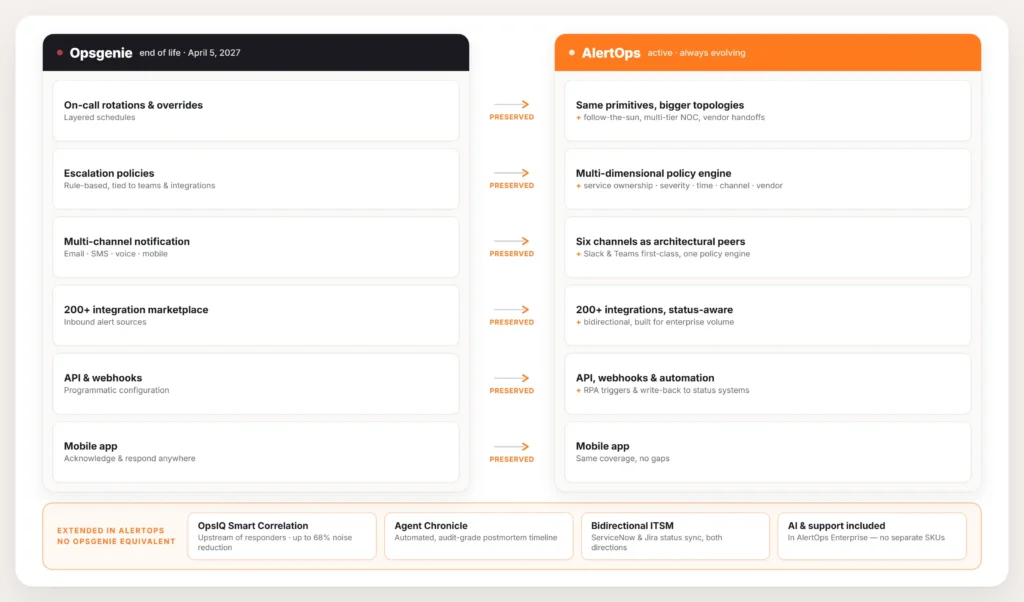
Side-by-side architecture diagram showing Opsgenie capabilities (rotations, escalation policies, multi-channel notification, 200+ integrations, API, mobile app) carrying forward into AlertOps, plus the AlertOps-only extensions (OpsIQ correlation upstream of responder queue, multi-dimensional policy routing, Agent Chronicle automated postmortems, bidirectional ServiceNow and Jira ITSM, AI and support in AlertOps Enterprise).
Side-by-side feature comparison
| Dimension | Opsgenie | AlertOps |
|---|---|---|
| Product status | End of sale June 4, 2025; full EOL April 5, 2027 | Active, independent, shipping continuously |
| On-call scheduling | Rotations, overrides, layered schedules | Same primitives + multi-region follow-the-sun, multi-tier NOC, vendor handoffs |
| Escalation policies | Rule-based, tied to teams and integrations | Multi-dimensional policy engine (service ownership, severity, time, channel, vendor) |
| Alert correlation | Basic deduplication | OpsIQ Smart Correlation Engine applying similarity modeling, NLP, and configurable thresholds |
| Alert noise reduction | Limited (downstream filtering) | up to 68% reduction in enterprise environments (AlertOps platform data) |
| Integrations | Broad marketplace (status: roadmap frozen) | 200+ connectors with bidirectional ITSM depth |
| Multi-channel response | Email, SMS, voice, push, chat | All six as first-class architectural peers through one policy |
| ITSM integration | One-way webhooks to Jira/ServiceNow | Bidirectional ServiceNow and Jira with status sync |
| Audit/compliance | Activity logs | Agent Chronicle automated postmortem generation |
| Mobile app | iOS + Android | iOS + Android |
| API | REST, webhook (no enhancement post-EOS) | REST, webhook, bidirectional, actively developed |
| AI capabilities | None native | OpsIQ correlation + agentic response + Agent Chronicle (AlertOps Enterprise) |
| Support model | Atlassian tiered (degrading post-EOS) | Responsive support in AlertOps Enterprise |
| Pricing structure | Per-responder, tiered | Custom, scaled to incident value rather than seat count |
| Migration tooling | N/A (this is the source) | Free migration team + automated tool included |
The comparison narrows to four areas where AlertOps preserves what Opsgenie did well, four areas where it extends, and three areas where it shifts the commercial structure.
What AlertOps preserves from Opsgenie
The Opsgenie strengths enterprise teams selected for were the on-call scheduling depth, the escalation policy flexibility, the integration marketplace breadth, and the standalone product focus. AlertOps preserves all four.
On-call scheduling depth. Rotations, layered schedules, overrides, time-zone-aware handoffs. The primitives Opsgenie made standard for the category are core to AlertOps. The schedule import from Opsgenie via the free migration tool reproduces the existing rotation logic without requiring rebuild. For environments that spent years tuning Opsgenie schedules across regions and teams, the operational investment carries forward.
Escalation policy flexibility. Opsgenie’s escalation primitives (timeouts, channels, fallbacks, conditional rules) imported into AlertOps as escalation rules and response policies. The translation handles the common case automatically. The exception cases (custom conditional logic, service-ownership-aware routing) become opportunities to take advantage of AlertOps’s multi-dimensional policy engine.
Integration marketplace breadth. Opsgenie’s integration catalog was a real competitive moat. AlertOps’s marketplace exceeds 200 connectors across observability, monitoring, ITSM, CMDB, chat, communication, and ticketing categories. The Opsgenie inbound integrations migrate as AlertOps inbound integrations, with payloads preserved.
Standalone product focus. Opsgenie was a standalone product. AlertOps is too. The platform is not a feature of a larger ITSM suite, not a post-acquisition product navigating a slow integration into a parent strategy, not a side bet in someone else’s portfolio. For organizations that valued Opsgenie’s standalone focus, AlertOps’s independent product status preserves that.
What AlertOps extends beyond Opsgenie
The capabilities Opsgenie did not address at enterprise scale are what AlertOps was built for. Four extensions matter.
Upstream AI correlation via OpsIQ. Opsgenie handled alerts as they arrived, with basic deduplication. AlertOps’s OpsIQ correlates signals from observability platforms across three dimensions (temporal proximity, service ownership, event signature) before a human responder is notified, so duplicates suppress, related signals group, and the responder receives enriched incidents rather than raw alert streams. AlertOps platform data shows up to 68% alert noise reduction in enterprise environments – for a 200-service environment generating a thousand raw alerts during a cascading incident, the responder receives approximately three hundred incidents.
Multi-dimensional policy routing. Opsgenie’s escalation policies were rule-based against teams and integrations. AlertOps’s routing engine evaluates service ownership, severity, time of day, vendor handoff conditions, channel preference, and compliance requirements in parallel through a single policy. The topology that Opsgenie expressed through stacked rules collapses into cleaner policies that match enterprise escalation reality. An AlertOps SE described the architectural distinction during a customer demo: “Unlike OpsGenie, we have decoupled everything. In OpsGenie it’s going to be in the team level – that’s where you set the escalation policies and the integration. Whereas in AlertOps, we have decoupled everything: a separate module for the groups and schedules, a separate module for escalation policies, and a separate module for the integrations. It basically makes it a little bit easier to manage.”
The same SE pitch addresses a specific Opsgenie pain customers raise during evaluation: “One of the key differentiators compared to OpsGenie is that you don’t need multiple layers for standard rotation. In something like OpsGenie, you have the option to escalate to next on call. The problem is if your team has flexible scheduling – say one person is primary, then they get a week off and then they’re secondary – configuring that in OpsGenie becomes substantially more complex.”
Multi-channel response as architectural peers. Opsgenie supported multi-channel notification. AlertOps coordinates Slack, Microsoft Teams, email, SMS, voice, and mobile as architectural peers through one policy. A single incident can simultaneously page an SRE through Slack, alert a vendor contact via SMS, place a voice call to a director, post to a NOC operator’s Teams channel, and push to the on-call engineer through the mobile app. All six paths fire through one policy engine and produce acknowledgments that close the loop back to the orchestration layer.
Compliance-grade audit via Agent Chronicle. Opsgenie’s activity logs were sufficient for internal review. They were not the artifact class regulated industries need for compliance reporting, vendor risk review, or customer audit requests. Agent Chronicle in AlertOps produces a structured, timestamped, immutable record of every alert ingested, every correlation performed, every escalation triggered, every responder action taken, and every resolution decision throughout the incident lifecycle. For financial services, healthcare, telecom, and other regulated environments, this is the artifact class an audit can be defended with.
Where the commercial structure shifts
Three commercial changes between Opsgenie and AlertOps matter for enterprise teams making the comparison.
Responsive support is included. Opsgenie support was tiered through Atlassian’s standard model and is degrading through the EOL window as resources reorganize toward JSM Operations. AlertOps Enterprise treats responsive support as part of the platform, not as a tier upgrade or priority SLA contract. For organizations whose incident response runs hot, that assumption is one of the structural differences that compounds across contract length.
AI is included. Opsgenie had no native AI capabilities. OpsIQ correlation, agentic response, and Agent Chronicle audit ship in the Enterprise plan rather than living behind an AIOps SKU. The contrast also holds against current alternatives. PagerDuty AIOps is a separate consumption SKU starting at $699 per month annual. Rootly’s flagship AI SRE agent is Enterprise-only. incident.io’s AI features require Pro or Enterprise. JSM’s Rovo AI agents require Premium. For organizations whose value from incident management is heavily AI-correlated, that pricing pattern matters in the second year of the contract.
Pricing scales to incident value rather than to seat count alone. Opsgenie was per-responder, which produced predictable but linearly scaling cost as the responder population grew. AlertOps pricing is structured around the value of the incidents the platform handles, with custom enterprise terms. For organizations whose responder population includes operators, vendor contacts, and stakeholders well beyond the engineering team, the AlertOps pricing model frequently produces lower TCO than the per-responder alternatives at enterprise scale.
When is Opsgenie still the right answer?
Through the EOL window, Opsgenie still functions. For organizations whose contract has more than a quarter of runway remaining and whose evaluation of alternatives is genuinely incomplete, renewing one more cycle to buy migration runway is sometimes the right choice. The platform works, the integrations continue firing, and the API responds – right up until the cutoff.
The window when Opsgenie is the right answer narrows month by month. By mid-2026, the runway to evaluate, decide, contract, migrate, and parallel-run is twelve to eighteen months. By late 2026 the runway compresses. By 2027 the team is making compressed-window decisions under deadline pressure that produce worse vendor selection.
For any team whose evaluation is mature and whose destination platform is ready, the renewal date is the moment to cut over. Avoiding the next Opsgenie commercial cycle and standing on the destination platform before deprecation accelerates is the cleaner outcome.
See how AlertOps handles the migration from Opsgenie at alertops.com/demo.
The honest assessment
Opsgenie was a strong standalone product whose parent company decided to absorb it into a different product. The features enterprise teams selected Opsgenie for (on-call depth, escalation flexibility, integration breadth, standalone focus) are preserved in AlertOps. The capabilities enterprise teams discovered Opsgenie did not address at scale (upstream AI correlation, multi-dimensional policy routing, multi-channel orchestration as architectural peers, compliance-grade audit) are what AlertOps was built to add. The commercial structure shifts in ways that favor enterprise responder populations: support included, AI included, scaling to incident value rather than only to seat count.
The migration off Opsgenie is forced. Choosing AlertOps as the destination preserves the operational investment in tuned escalation logic, extends it with orchestration-layer capabilities, and stands on a commercial structure that holds up across enterprise contract lengths. For Opsgenie users whose evaluation surfaces orchestration as the architectural fit, AlertOps is the platform built for that layer.
Book a demo at alertops.com/demo to see how AlertOps compares to your specific Opsgenie environment and what the migration looks like.
Frequently asked questions about Opsgenie vs AlertOps
Is AlertOps a good Opsgenie alternative?
For enterprise operations teams running hundreds of services with multi-channel response, bidirectional ServiceNow or Jira ITSM, and compliance-grade audit requirements, AlertOps is the architectural fit because it operates at the incident orchestration layer with OpsIQ alert correlation, multi-dimensional policy routing, and Agent Chronicle audit timeline. AlertOps Enterprise bundles support, AI, and on-call. For Slack-native engineering teams in the 100-500 engineer band, alternatives like incident.io or Rootly fit a different operating model.
What is AlertOps and how does it compare to Opsgenie for on-call alerting?
AlertOps is an AI-first incident orchestration platform for enterprise operations teams. For on-call alerting specifically, AlertOps preserves the Opsgenie primitives (rotations, layered schedules, overrides, time-zone-aware handoffs) and extends them with multi-tier NOC support, vendor handoffs, follow-the-sun coverage, and compliance-driven scheduling. On-call is a core capability in AlertOps Enterprise, not a separately licensed module.
Does AlertOps cost more than Opsgenie?
Pricing depends on responder population and incident value. AlertOps is structured to scale to incident value rather than only to seat count, which frequently produces lower TCO than per-responder alternatives at enterprise scale. The comparison that matters is the destination platform total cost including all modules the team actually uses, not the sticker price of the headline seat.
Can AlertOps replace all Opsgenie features?
Yes. AlertOps preserves the Opsgenie feature surface (on-call scheduling, escalation policies, multi-channel notification, integration marketplace, API, mobile app) and extends each into the orchestration layer with OpsIQ correlation, multi-dimensional routing, bidirectional ITSM, and Agent Chronicle compliance-grade audit.
How does the migration from Opsgenie to AlertOps work?
AlertOps provides a free migration team and automated tool. The tool captures escalation policies, on-call schedules, integrations, and user mappings from the Opsgenie API and reproduces them in AlertOps. Cutover is incremental rather than rebuild-from-scratch. Total elapsed time runs two to six weeks for smaller environments and six to twelve weeks for enterprise environments with hundreds of integrations.
What does AlertOps have that Opsgenie doesn’t?
Four primary extensions: OpsIQ AI alert correlation at the ingestion layer (roughly 68% noise reduction in enterprise environments per AlertOps platform data), multi-dimensional policy routing that evaluates service ownership, severity, time, channel, and vendor handoff in parallel, multi-channel response coordinating Slack/Teams/SMS/voice/email/mobile as architectural peers, and Agent Chronicle automated postmortem generation (with compliance-grade audit trail).
Should I migrate from Opsgenie to AlertOps now or wait?
For teams whose Opsgenie evaluation of alternatives is mature and whose destination platform is ready, migrating before the next renewal date avoids the next Opsgenie commercial cycle and provides time for clean parallel-run cutover before the deadline. For teams whose evaluation is incomplete, renewing one more Opsgenie cycle to buy migration runway is sometimes the right choice. The runway compresses month by month as the EOL date approaches.


